---Spark集群搭建
Docker-compose中的spark-master,spark-worker组成Spark集群。spark-master与minio1建立容器链接,后续需要Spark读写MinIO存储。
---MinIO Client搭建
Docker-compose中的minio-mc对应MinIO Client。MinIO Client提供了一些命令如ls, cat, cp, mirror, diff, find等,实现与MinIO云存储服务的交互。minio-mc与minio1建立容器链接,后续需要使用minio-mc创建bucket。
---启动容器
执行docker-compose up -d命令,启动所有容器
访问http://127.0.0.1:9001/确认MinIO存储服务正常
访问http://127.0.0.1:8080/确认Spark集群正常
---配置MinIO-Client
执行docker exec -it cas001-minio-mc /bin/sh进入MinIO-Client
执行ping S3_server确认MinIO存储服务的IP地址,例如192.168.144.3
执行以下语句,创建一个名为spark-test的bucket,并传入一份test.json文件
mc config host add myminio http://192.168.144.3:9000 minio minio123
mc mb myminio/spark-test
mc cp test.json myminio/spark-test/test.json
执行mc ls myminio即可看到创建的bucket
---Spark读写MinIO存储
确保配置MinIO-Client执行成功,有对应的bucket和test.json文件存在
执行docker exec -it cas001-spark-master /bin/bash进入cas001-spark-master容器
执行ping S3_db确认MinIO 存储服务IP地址,例如192.168.144.3
---配置Spark集群
Spark访问MinIO存储需要一些依赖包,具体参考这里。其中必须添加的两个jar包是:hadoop-aws-2.7.3,aws-java-sdk-1.7.4。
Hadoop安装文件夹中包含了上述两个jar包,可以在Hadoop安装目录下执行find /hadoop_path -name hadoop-aws*.jar和find /hadoop_path -name hadoop-aws*.jar来查找jar包的位置。
如果本机没有安装Hadoop,即使用的Spark安装包如spark-2.4.5-bin-hadoop2.7.tgz所示, 则需要先确认对应的Hadoop具体版本(可以查看spark/jars/下与Hadoop相关的jar包来确认hadoop版本),然后去下载对应的jar包。
jar包准备好后,执行bash copy_dependencies.sh将对应的jar包拷贝到spark-master和spark-worker的spark安装路径jars文件夹下,copy_dependencies.sh的内容如下:
#!/bin/bash
SPARK_MASTER="cas001-spark-master"
SPARK_WORKER="cas001-spark-worker"
docker cp ./dependencies/. ${SPARK_MASTER}:/spark/jars
docker cp ./dependencies/. ${SPARK_WORKER}:/spark/jars---Spark读写MinIO存储
确保配置MinIO-Client执行成功,有对应的bucket和test.json文件存在
执行docker exec -it cas001-spark-master /bin/bash进入cas001-spark-master容器
执行ping S3_db确认MinIO 存储服务IP地址,例如192.168.144.3
使用spark-shell读取MinIO存储
执行如下命令,打开spark-shell
./bin/spark-shell \
--conf spark.hadoop.fs.s3a.endpoint=http://192.168.144.3:9000 \
--conf spark.hadoop.fs.s3a.access.key=minio \
--conf spark.hadoop.fs.s3a.secret.key=minio123 \
--conf spark.hadoop.fs.s3a.path.style.access=true \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem
执行如下命令读取MinIO存储
val b1 = sc.textFile("s3a://spark-test/test.json")
b1.collect().foreach(println)---使用spark-submit提交delta-lake作业
执行bash copy-delta-lake-demo.sh拷贝程序所需的jar包,copy-delta-lake-demo.sh具体内容如下:
#!/bin/bash
SPARK_MASTER="cas001-spark-master"
docker cp ./delte-lake-demo/. ${SPARK_MASTER}:/spark/examples执行如下命令,提交作业
./bin/spark-submit --master spark://spark-master:7077 \
--conf spark.delta.logStore.class=org.apache.spark.sql.delta.storage.S3SingleDriverLogStore \
--conf spark.hadoop.fs.s3a.endpoint=http://192.168.144.3:9000 \
--conf spark.hadoop.fs.s3a.access.key=minio \
--conf spark.hadoop.fs.s3a.secret.key=minio123 \
--conf spark.hadoop.fs.s3a.path.style.access=true \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--jars /spark/examples/delta-core_2.11-0.5.0.jar \
--class com.delta.Run examples/original-deltaLake2-1.0-SNAPSHOT.jar s3a://spark-test/ delta21 schemaCheck21
# Run 主程序参数:S3_bucket:s3a://spark-test/ ,S3_bucket文件名1:delta21 ,S3_bucket文件名2:schemaCheck21
---Spark3(包含Deleta Lake)
# 2.spark3(包含Deleta Lake)
# 2.1 spark-master
spark:
image: datamechanics/spark:jvm-only-3.1-latest
hostname: spark
command: /opt/spark/sbin/start-master.sh
environment:
- "SPARK_MASTER_HOST=spark"
ports:
- "8080:8080"
- "7077:7077"
# 2.2 spark-worker
worker:
image: datamechanics/spark:jvm-only-3.1-latest
hostname: worker
command: /opt/spark/sbin/start-worker.sh
environment:
- "SPARK_MASTER_HOST=spark"
ports:
- "8080:8080"
- "7077:7077"
---spark 集成delta lake 以及minio s3
-运行命令
# 1. 进入根目录
cd
# 2. spark 集成delta lake 以及minio s3
./bin/spark-shell \
--packages io.delta:delta-core_2.12:1.0.0,org.apache.hadoop:hadoop-aws:3.2.0 \
--conf "spark.hadoop.fs.s3a.access.key=minio" \
--conf "spark.hadoop.fs.s3a.secret.key=minio123" \
--conf "spark.hadoop.fs.s3a.endpoint=http://10.0.0.198:9000" \
--conf "spark.databricks.delta.retentionDurationCheck.enabled=false" \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
# 3. 创建delta lake table--先在minio中创建名为delta-lake的bucket,然后生成随机数保存都firstdemo中
spark.range(50000000).write.format("delta").save("s3a://delta-lake/firstdemo")-运行示例
185@spark:~/work-dir$ cd
185@spark:~$ ./bin/spark-shell \
--packages io.delta:delta-core_2.12:1.0.0,org.apache.hadoop:hadoop-aws:3.2.0 \
--conf "spark.hadoop.fs.s3a.access.key=minio" \
--conf "spark.hadoop.fs.s3a.secret.key=minio123" \
--conf "spark.hadoop.fs.s3a.endpoint=http://10.0.0.198:9000" \
--conf "spark.databricks.delta.retentionDurationCheck.enabled=false" \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
:: loading settings :: url = jar:file:/opt/spark/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /opt/spark/.ivy2/cache
The jars for the packages stored in: /opt/spark/.ivy2/jars
io.delta#delta-core_2.12 added as a dependency
org.apache.hadoop#hadoop-aws added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-b3b3485b-6bb5-42b7-a4fc-5a6ceee32dbe;1.0
confs: [default]
found io.delta#delta-core_2.12;1.0.0 in central
found org.antlr#antlr4;4.7 in central
found org.antlr#antlr4-runtime;4.7 in central
found org.antlr#antlr-runtime;3.5.2 in central
found org.antlr#ST4;4.0.8 in central
found org.abego.treelayout#org.abego.treelayout.core;1.0.3 in central
found org.glassfish#javax.json;1.0.4 in central
found com.ibm.icu#icu4j;58.2 in central
found org.apache.hadoop#hadoop-aws;3.2.0 in central
found com.amazonaws#aws-java-sdk-bundle;1.11.375 in central
:: resolution report :: resolve 350ms :: artifacts dl 9ms
:: modules in use:
com.amazonaws#aws-java-sdk-bundle;1.11.375 from central in [default]
com.ibm.icu#icu4j;58.2 from central in [default]
io.delta#delta-core_2.12;1.0.0 from central in [default]
org.abego.treelayout#org.abego.treelayout.core;1.0.3 from central in [default]
org.antlr#ST4;4.0.8 from central in [default]
org.antlr#antlr-runtime;3.5.2 from central in [default]
org.antlr#antlr4;4.7 from central in [default]
org.antlr#antlr4-runtime;4.7 from central in [default]
org.apache.hadoop#hadoop-aws;3.2.0 from central in [default]
org.glassfish#javax.json;1.0.4 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 10 | 0 | 0 | 0 || 10 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-b3b3485b-6bb5-42b7-a4fc-5a6ceee32dbe
confs: [default]
0 artifacts copied, 10 already retrieved (0kB/9ms)
21/11/04 05:10:33 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/11/04 05:10:41 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Spark context Web UI available at http://localhost:4041
Spark context available as 'sc' (master = local[*], app id = local-1636002641781).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.1
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_312)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.range(50000000).write.format("delta").save("s3a://delta-lake/firstdemo")
21/11/04 05:12:09 WARN MemoryManager: Total allocation exceeds 95.00% (906,992,014 bytes) of heap memory
Scaling row group sizes to 96.54% for 7 writers
21/11/04 05:12:09 WARN MemoryManager: Total allocation exceeds 95.00% (906,992,014 bytes) of heap memory
Scaling row group sizes to 84.47% for 8 writers
21/11/04 05:12:14 WARN MemoryManager: Total allocation exceeds 95.00% (906,992,014 bytes) of heap memory
Scaling row group sizes to 96.54% for 7 writers
# 数据湖架构
大多数公司都有大量的业务数据,这些数据通常孤立在各种存储系统中,包括数据库和数据仓库。为了充分利用这些数据资产,您应该将数据集中并整合到统一的数据存储中,以增强分析能力。
通过数据湖架构,组织可以更大规模地简化跨职能企业分析。查询数据湖和收获丰富洞察的能力带来了巨大的商业价值。当正确的建立和部署,数据湖给你的能力:
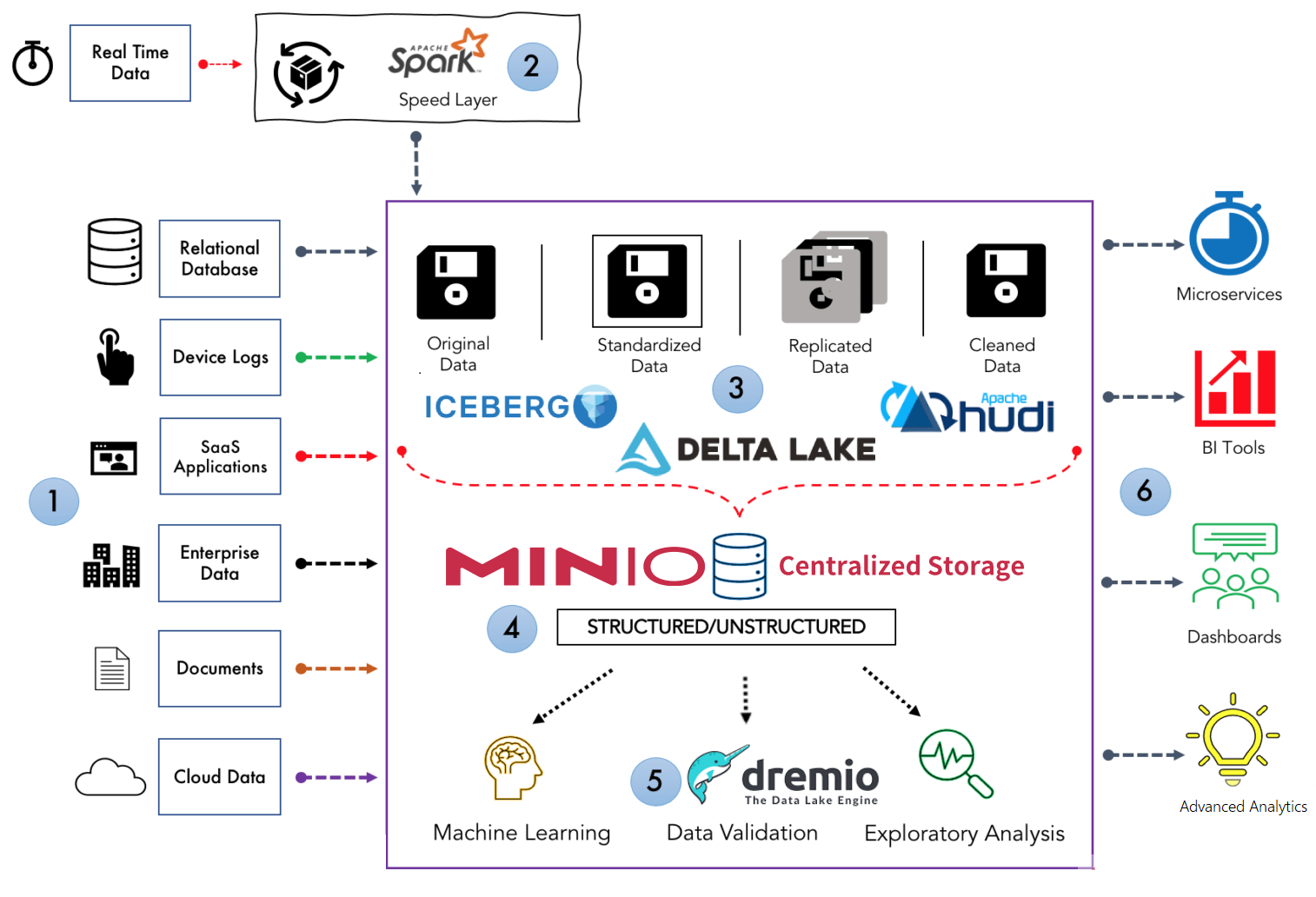
以下是对数据湖架构的组件1到6的简要说明。
数据源:包括大量结构化和非结构化数据源输入数据湖。其中包括关系数据库、设备日志、企业数据、SaaS 数据、文档、云数据等等。
数据处理: 数据湖包含所有类型的数据资产,其中大部分不是实时产生的。因此,加载到数据湖中的大多数数据都以批处理格式存储。在将数据放入湖中之前,使用lambda 架构或Kafka Streams等实时数据框架(如: Spark)进行流处理。
数据转化:虽然数据湖是用于保存数据的统一中央存储库,但这些数据不会未经任何清理或处理就加载到数据湖中,并可以将其处于更好的结构或格式(如:DELTA LAKE/ICEBERG/HUDI)中以便于分析。
数据存储:这里是存储不同类型数据的地方。MinIO等工具用于存储目的。
数据分析: 数据湖允许企业中的各个团队使用他们选择的分析工具和框架(如: Dremio)访问数据。分析师可以利用这些数据,而无需将其移动到单独的存储中进行处理、分析、提炼或转换。
报告: 数据湖连接到现代商业智能工具,如 Apache Superset、Metabase 或 Tableau,用于准备数据以进行分析和构建报告。
对于想要存储多种类型的数据并从其数据资产中获得巨大价值的企业来说,数据湖非常强大。


